ubiquitous gnocchi...
… under the cloud, peering through the fog, reaching for the edge
In late 1996, a group of executives at Compaq Computers were thinking about the future of the Internet business and coined the term “cloud computing”. The original vision of “cloud computing-enabled applications” has grown to provide every “as-a-Service” derivative imaginable, funding a multi-billion dollar industry which Gartner estimates to hit nearly $250 billion in 2017.
Everything that’s popular in technology is replaced by something else. It always goes away… if you want to predict the future, subtract something important today, and replace it with something else.
– Peter Levine, 2016, The End of Cloud Computing
As with all things in technology though, it’s on to the next one and what’s old is often made new again (i think this might explain the high hipster rate in technology [source: me, 2017]). The cyclic nature of technology is changing today’s centralised world of cloud computing to an impending decentralised world of edge computing. The Internet of Things (IoT) is the next stage of computing where computing is mobile and massively data driven by sensors.
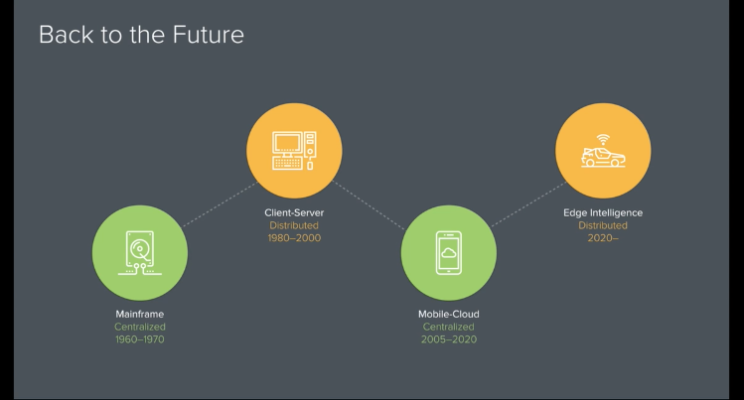 Peter Levine, 2016, The End of Cloud Computing
Peter Levine, 2016, The End of Cloud Computing
In IoT, processing moves to the edge where devices must sense, infer, and act in real-time. While this processing can be done more quickly in the cloud, if the devices themselves can do the computing, the latency and bandwidth load can be saved on the network. For reference, a self-driving car generates over 10GB of data per mile and requires real-time processing on the data.
The most prominent use case for edge computing is automated vehicles where companies such as Waymo and Intel are adding more and more sophisticated hardware to vehicles. In addition to that, mobile device and semiconductor companies such as Huawei, ARM, and Apple are building hardware to better handle tasks locally to allay privacy concerns and to piggyback off the even bigger AI trend.
That said, even as the world begins its slow shift to edge computing, cloud computing remains a relevant endpoint for providing massive computing on batch or asynchronous tasks. In machine learning, the large training sets required for learning will be done centrally and the neural net will be propagate to the edge nodes where it will be executed.
gnocchi in the cloud
Gnocchi is a time-series database with origins in the cloud computing space. It was built to capture millions of metrics across tens of thousands of virtual machines in the cloud using a horizontally scalable architecture.
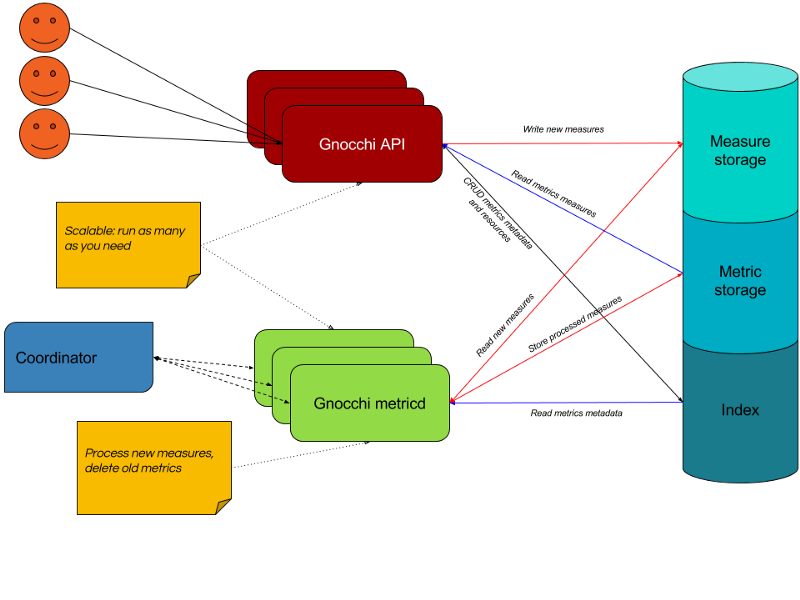 Gnocchi basic architecture (gnocchi.xyz 2017)
Gnocchi basic architecture (gnocchi.xyz 2017)
In most scenarios, the classic deployment of Gnocchi will be able to cope with the incoming load: API workers can be added to handle more requests; additional metricd workers can be deployed to process greater numbers of metrics; and storage capacity can be configured to grow ‘infinitely’ when backed by one of the object storage drivers such as Ceph, Swift, or S3.
While building Gnocchi, one of the use cases targeted was a centralised monitoring system for a multi-cloud environment. Attempting to support this use case, we recognised that the distribution of processing units across clouds, regions, or devices raised additional requirements. The dissemination of resources increases the number of individual nodes to monitor and adds additional transportation considerations.
For instance, when monitoring multiple clouds, there are potentially:
- cost per transactions and cost per data in and out of the cloud
- total bandwidth capacity in and out of the cloud
- round-trip overhead of a REST call from one cloud to another
These same issues are applicable lower in the stack by replacing cloud with region, device, or application which forces us to make changes to our Gnocchi deployment strategy.
disclaimer: there are many legal issues with collating data across borders which is arguably your biggest issue with monitoring multiple clouds.
inspired by StatsD
StatsD is a daemon originally released by Etsy back in 2011 to help developers instrument an application with a simple goal of making dope graphs… and monitoring application health.
 Graphite+StatsD (Etsy 2011)
Graphite+StatsD (Etsy 2011)
Users of StatsD have many reasons for adopting the daemon including its low footprint and support across many languages and backends. More importantly, it provides a simple daemon deployed local to the source and allows for efficient data transfer from source to storage.
gnocchi everywhere
Attempting to use the same deployment principles as StatsD, Gnocchi can be deployed in a similar manner leveraging its componentised design.
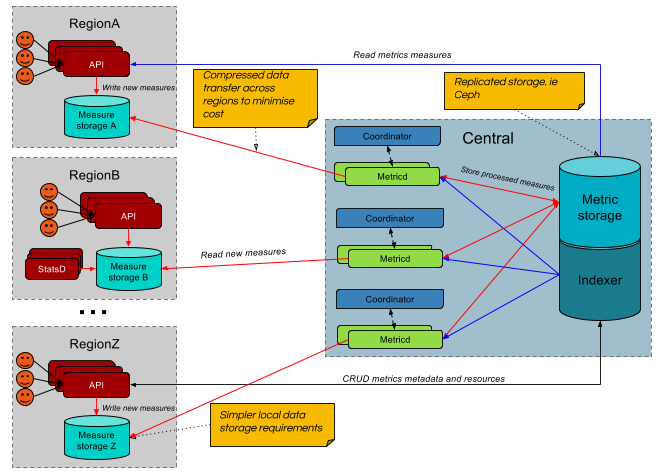 Distributed Gnocchi
Distributed Gnocchi
One of the big issues with multi-cloud monitoring is the distance between the resource being tracked and the storage of its metrics. By deploying the API and incoming measure storage closer to the resources, data can be sent with minimal latency. Additionally, as each regional incoming storage has less resources to track, a lightweight, performant incoming storage solution such as Redis can be leveraged. It is also possible to create a cache of the indexer at each region to reduce the need to query an off-site database.
The deployment location of the regional metricd daemons may vary depending on environment. Metricd services can be deployed centrally and share a coordinator service while pulling ungrouped, uncompressed, serialised measures from the regional incoming stores. This also reserves all the processing on the central cloud environment.
Alternatively, it can deployed regionally and pull in grouped, compressed, serialised back window data from the measure storage and send back (potentially) compressed aggregate data. When Gnocchi is deployed to aggregate in bulk rather than real-time, deploying the metricd services on regional sites will probably yield better network usage.
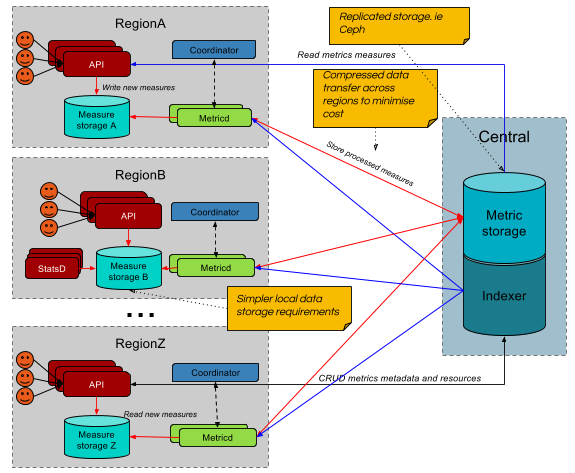 Regionally deployed API and MetricD services
Regionally deployed API and MetricD services
By deploying multiple ‘local’ Gnocchi services, we are able to effectively distribute smaller service requirements across sites and collate them centrally more efficiently.
improving the edge use case
As previously mentioned, Gnocchi was built around the cloud context so it does not perfectly cover edge use cases. Specifically, some features that may be useful would be to:
- Encrypt the transmission data. Currently, the data transferred across storage nodes is a custom format that is compressed. To make it truly secure, it’d be nice to encrypt the data as it’s move across nodes/sites/regions/clouds
- Lightweight API. Gnocchi’s REST API is built to do everything. It provides all CRUD functionality and additional re-aggregation and cross-metric aggregation. This results in quite a large memory footprint. A streamlined API or StatsD service can better serve the lightweight, Gnocchi-on-the-Edge use case.
- Multi-consumer incoming measures storage. Currently, the incoming measure storage is cleared as each measure is aggregated to metric storage. As processing moves to the node, it may be useful for the local node to have access to the data as well.